
Rappels OS#
Quelques notes sur le cours de système d’exploitation.
Qu’est-ce qu’un processus#
On peut distinguer deux types de systèmes d’exploitation (OS) :
Monotâche : Une seule tâche est en cours d’exécution et monopolise toutes les ressources (Même si vous possédez un EPYC avec 96 cœurs). Ce genre d’OS est principalement utilisé dans des systèmes embarqués
Multitâches : Plusieurs tâches sont en concurrence sur les ressources. Autrement dit, soit elle s’alterne en suivant une certaine logique, ou elles s’exécutent en parallèle.
Maintenant, un OS classique que l’on va utiliser dans nos machines de tous les jours doit pouvoir gérer plusieurs tâches en même temps, sinon il est tout bonnement impossible d’avoir un système interactif. Riens que votre interface utilisateur représente plusieurs tâches qui doivent cohabiter et s’échanger des données. Et ce pauvre OS doit faire vivre tout ce joli monde tout en faisant attention à ne pas les laisser mourrir de fin (starvation) en leur n’accordant pas les ressources nécessaires.
Dans un OS, on parle principalement de processus. On peut voir un processus comme un espace mémoire contenant du code et des données. Quand l’OS veut faire exécuter un certain processus, il aiguille le CPU vers le bon code (espace mémoire) pour faire le travail qui impliquera surement des lectures et des écritures dans cette espace mémoire qu’on nomme processus.
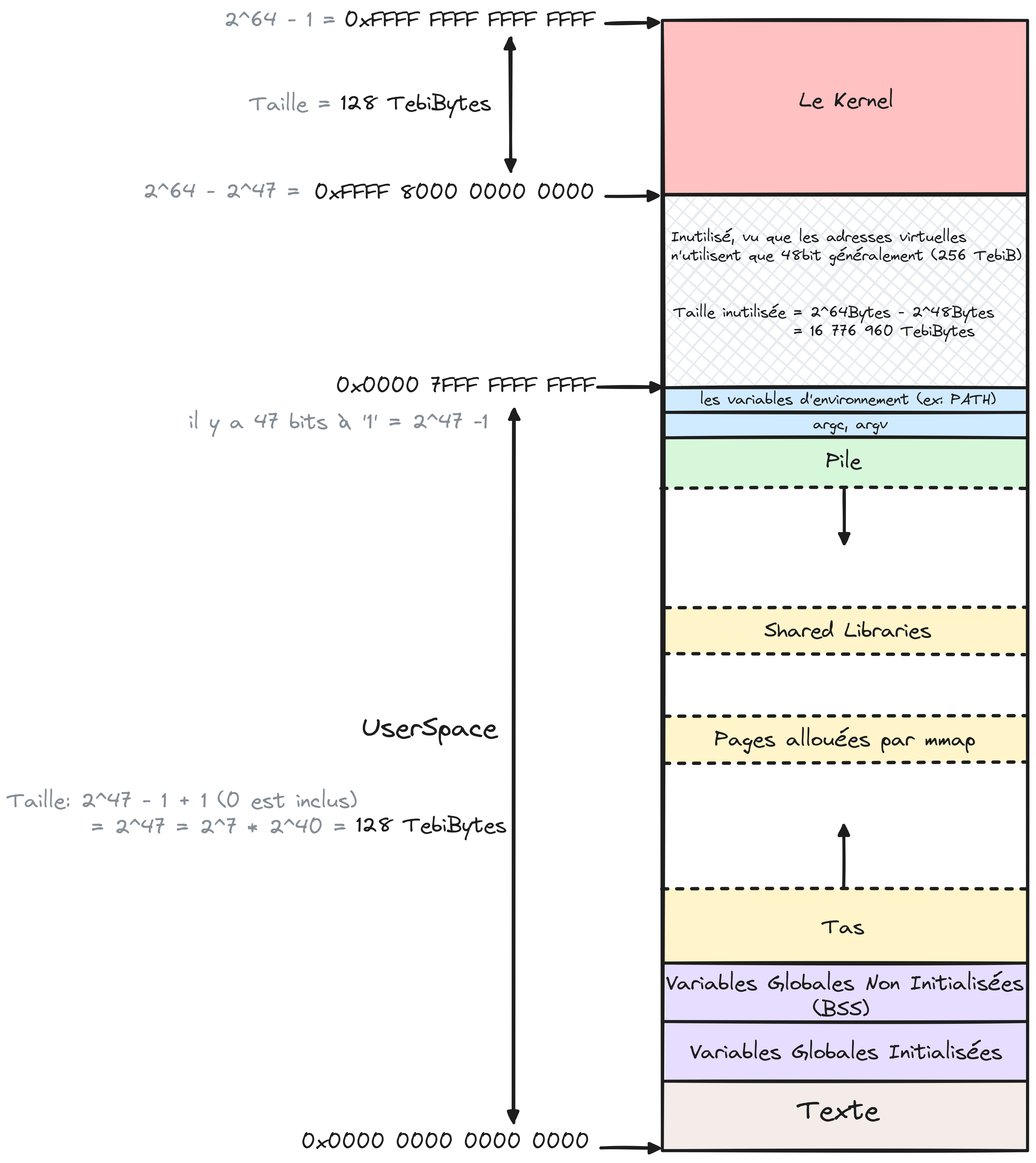
Figure 1 Mémoire virtuelle d’un processus dans le kernel linux sous x86_64. Notez que seulement 48-bits sont reellement utilisés. Kernel Docs#
La figure simplifie les différents blocs du Kernel en un seul pour ne pas complexifier encore plus la figure. Retenez juste que dans le le bloc kernel existe une pile pour ce processus utilisée lors de l’exécution de code kernel pour ce même processus.
Dans ce qui suit je vais utiliser le terme tâche pour mieux définir les threads plus tard.
La structure qu’on appelle le PCB (process control block) existe pour que l’OS ne fasse pas n’importe quoi lors de la gestion des tâches existantes, notamment avec toute l’histoire de mémoire virtuelle.
Cette structure est immense, puisque pour satisfaire tout ce beau monde, il faut un maximum d’informations. À la fois pour optimiser l’ordonnancement (qui exécuter) et aussi pour toujours garder la stabilité de tout le système lors des réponses aux demandes (les syscalls) des tâches. Ainsi, un processus mal attentionné ne va pas pouvoir contrôler tout le système, par exemple.
Prenez comme exemple la
task_structde Linux que vous pouvez voir ici, la structure ne se termine qu’à la ligne1661. Le kernel faisant le lien matériel-logiciel, doit réussir à abstraire les différentes architectures supportées au logiciel.
Question :
Si c’est le code du processus qui est exécuté par le CPU, quand est-ce que le code du kernel est exécuté ? Y a-t-il un processus kernel ?
Réponse:
Ce qu’on appelle le kernel est une partie du système d’exploitation. C’est tout le code de l’OS qui est exécuté en mode privilégié qui permet de gérer les interruptions du CPU et d’accéder au matériel des systèmes. Ce code est présent chez tous les processus d’un système, à la manière des bibliothèques partagées, où la pagination et son concept de monde virtuel fait en sorte qu’il existe une seule copie du kernel dans la mémoire physique.
Pour faire simple, quand une interruption est levée par le CPU ou que le processus fait un syscall, ce dernier se retrouve à devoir exécuter le code du kernel pour gérer cette interruption ou ce syscall. Le kernel est omniprésent dans son système, il intervient quand il faut pour répondre à une demande et veille toujours à son bon fonctionnement.
Note
Pour ceux qui veulent savoir comment les adresses kernel sont traduites alors qu’elles sont au delà des 48-bits. Comprennez que les adresses utilisateurs ne mettent jamais à 1 le 48éme bit (d’où le 7 dans l’adresse finale et non F). Ce dernier par contre est toujours à 1 dans les adresses kernel, et avec cette unique changement on explorera un tout autre bloc de 128 TebiBytes différent de celui du UserSpace (Les 4 FFFF supérieurs ne sont jamais lus par le matériel).
Le changement de contexte (changement de tâche)#
Quand le CPU exécute du code (une suite d’instructions) il interagit avec la mémoire principale (cache et RAM) mais avant tout, avec ses registres. La lecture et écriture en mémoire est lentes par rapport au CPU, le temps d’un simple accès RAM (~200-300 cycles, ref) est l’équivalent de plus de 200 instructions utilisant que les registres (voir même le cache L1). C’est pour cela qu’on veut que l’accès en mémoire principale ne soit fait que si obligatoire.
Le cache existe pour accélérer les accès mémoire, le cache est plus de 10x plus rapide que la RAM classique.
Un accès en mémoire peut être plus lent, ça dépend de la taille des données lues. Plus la taille des données est grande, plus le temps d’accès croît. En vérité, le burst mode (mode rafale) et d’autres optimisations matérielles et logicielles permettent d’avoir des temps d’accès acceptables pour les données lourdes.
Comme décrit précédemment, un OS multitâche doit gérer plusieurs tâches et faire en sorte de donner du temps d’exécution à ses dernières de façon équitable ou pas. Quand une nouvelle tâche (N) est en cours d’exécution, celle d’avant (P) n’est pas nécessairement fini et elle doit être rechargée dans le futur pour qu’elle puisse se finir correctement.
Vu que la nouvelle tâche (N) a le CPU à elle toute seule, elle va pouvoir utiliser ses registres comme elle le souhaite, après tout, c’est ce que promet l’OS pour la tâche qu’il a choisie à être exécutée.
Grâce à la virtualisation et toute la gestion de la pagination, les modifications en mémoire des tâches précédentes sont en sécurités. Par contre, les valeurs qu’elles avaient dans les registres du CPU sont très probablement perdues à jamais.
Pour ne pas avoir à refaire tout le travail déjà fait par la tâche P qui a perdu le CPU, une sauvegarde en mémoire principale est créee avant le changement de tâche. La sauvegarde contient les valeurs des registres juste avant le changement de tâches. Ainsi, au retour de la tâche P elle pourra reprendre son exécution comme si elle ne s’est jamais arrêtée.
Lors d’un changement de tâches, l’OS doit mettre à jour les structures de données qui lui permettent de gérer N et P, maintenant N est en état d’exécution alors que P repasse en mode “je suis prête”. Naturellement, pour ne pas causer de conflits entre le monde virtuel de N et celui P, l’OS doit changer l’adresse de la table des pages présente dans le registre qui doit la contenir (CR3 pour l’architecture x86).
Si vous regardez bien la task_struct vous verrez qu’il ne y a pas d’attribut pour enregistrer les valeurs des registres. En vrai, il existe ce qu’on appelle une pile de kernel que le kernel utilise lors de l’exécution de son code et enregistre dessus des données supplementaires necessaires à la gestion d’une tâche.
Du coup, une tâche possède à la fois une pile classique(accessible en mode utilisateur) et une pile kernel (accessible qu’en mode kernel).
La taille de cette pile kernel est fixée à la compilation du kernel, et elle est generalement égale à 2 pages (8184 octets = 8Kib).
Quelques exemples d’algorithmes d’ordonnancement#
Il existe plusieurs algorithmes d’ordonnancement, chacun avec ses avantages et incovenients. Mais avant on doit parler des deux grosses catégories de tâches et des deux types d’ordonnancement.
Types de tâches#
Durant l’exécution d’une tâche, elle peut faire appelle aux périphériques connectés. Soit, elle leur envoie des données, par exemple une image à afficher sur le périphérique écran, ou recevoir une donnée de la part d’un périphérique, par exemple, la touche appuyée sur le clavier.
Voyez-vous, les périphériques sont très lents par rapport au CPU, ainsi une écriture ou une lecture depuis un périphérique peut être l’équivalent de millions d’instructions CPU simples. Pour ne pas gâcher autant de temps à ne rien faire, dans les OS modernes, une tâche attendant la fin d’une écriture ou d’une lecture perd le CPU et est mise en état d’attente jusqu’à la réception de la réponse du périphérique (fin d’écriture ou les données lues). Une fois la réponse reçue, la tâche est remise en état “je suis prête” et pourra poursuivre son exécution très prochainement.
La fameuse mesure IOPS représente le nombre d’opérations d’entrées et de sorties possibles dans la seconde par un périphérique. De nos jours, avec les SSD pouvant atteindre le million d’IOPS, on arrive à avoir des périphériques de stockage permettant une meilleure interactivité, alors que les disques durs (HDD) sont très lents en comparaison (HDD vs SSD).
On aime catégoriser les tâches en deux grandes familles :
Les tâches I/O bound: les tâches qui passent la majorité de leur temps à attendre les réponses de périphériques (exemples : un éditeur de texte, l’interface graphique).
Les tâches CPU bound: elles n’en nullement besoin de périphériques (très rares) ou très rarement, autrement dit, elle passe la majorité de leur temps à exécuter du code CPU (exemple : votre programme Fibonacci).
Par contre, il existe des tâches qui utilisent les deux de manière équilibrée, par exemple un jeu vidéo effectue plein de calcul pour dessiner une scène, mais il interagit aussi avec vos périphériques pour lire vos commandes et émettre la scène calculée sur votre écran. Mais pour la suite de l’histoire, disant qu’il n’existe que les deux extrémités (I/O bound et CPU bound).
Les périphériques étant le matériel utilisé par l’utilisateur pour interagir avec son système, les tâches I/O bound doivent rapidement poursuivre avec leur exécution pour qu’utilisateur puisse avoir une meilleure expérience (pour que le système soit interactif).
Types d’ordonnancement#
Il existe deux types d’ordonnancement :
Non-préemptif : L’ordonnanceur ne peut choisir une nouvelle tâche que si la tâche précédente à d’elle-même choisie de lâcher le CPU (soit attend une I/O ou s’est terminée).
Préemptif : L’ordonnanceur peut faire arrêter une tâche (en cours d’exécution) et en choisir une nouvelle à n’importe quel moment. Si la tâche lâche d’elle-même le CPU, l’ordonnanceur en choisie une nouvelle.