
Les registres et l’adressage#
Registres en x86_64#
Il existe plusieurs types de registres dans l’architecture x86_64:
General Purpose Registers
The pointer register
Flag Register
Control Registers
Debug Registers
Model-Specific Register
XMM Registers
x87 Float registers (en pratique, les XMM registers les ont remplacés)
On va principalement parler des deux premieres familles de registres.
General Purpose Registers#
En x86_64 les registres généralistes ont une taille maximale de 64-bits (8 octets). Il existe 16 registres dans cette famille, dont certain ont une utilisation spécifique.
Les registres sont :
%rax,%rbx,%rcx,%rdx: version 64-bits des registres: A, B, C, D.%rdp,%rsp: version 64-bits des registres de gestion de la pile: BP(base pointer) et SP (stack pointer).%rsi,%rdi: version 64-bits des registres pour la copie de données: SI(source index) et DI(destination index).%r8,%r9,%r10,%r11,%r12,%r13,%r14,%r15: registres 64-bits introduit avec l’architecture x86_64 (inexistant en architecture x86 32-bits).
Ces registres peuvent être accédés de différentes manières, on peut faire en sorte d’accéder que certains octets des registres.
Pour commencer, on va examiner les registres traditionnels (A,B,C,D). Comme le montrent les figures et code suivants, chaque nom permet de spécifier les octets à lire ou à écrire.
; source:
.global main
main:
movabsq $0x71ff9b005c4e258a, %rax
movl %eax, %ebx
movb $0x41, %ah
movb $0x41, %al
movw $0x51, %ax
movl $0x41, %eax
movq $0x51, %rax
movw %ax, %bx
ret
; compilé (objdump):
;main:
; 1129: 48 b8 8a 25 4e 5c 00 movabs $0x71ff9b005c4e258a,%rax
; 1130: 9b ff 71
; 1133: 89 c3 mov %eax,%ebx
; 1135: b4 41 mov $0x41,%ah
; 1137: b0 41 mov $0x41,%al
; 1139: 66 b8 51 00 mov $0x51,%ax
; 113d: b8 41 00 00 00 mov $0x41,%eax
; 1142: 48 c7 c0 51 00 00 00 mov $0x51,%rax
; 1149: 66 89 c3 mov %ax,%bx
; 114c: c3 ret
On remarque que les deux instructions
movl $0x41, %eaxetmovq $0x51, %raxse comportent exactement de la même manière dans ce cas de figure. Tout en ayant des tailles différentes: la version avec%eaxutilisant 2 octets de moins.Pour des raisons de performances de calculs en 32-bits (comme expliqué ici) amd a fait en sorte de forcer les 32-bits de poids fort à zéro.
Retenez juste que les instructions sur les 32-bits de poids faible forcent implicitement les 32-bits de poids fort d’un registre 64-bits à zéro.
Les autres registres hérités (SI,DI,SP,BP) ne permettent pas d’accéder à leur deuxième octet comme les registres (A,B,C,D).
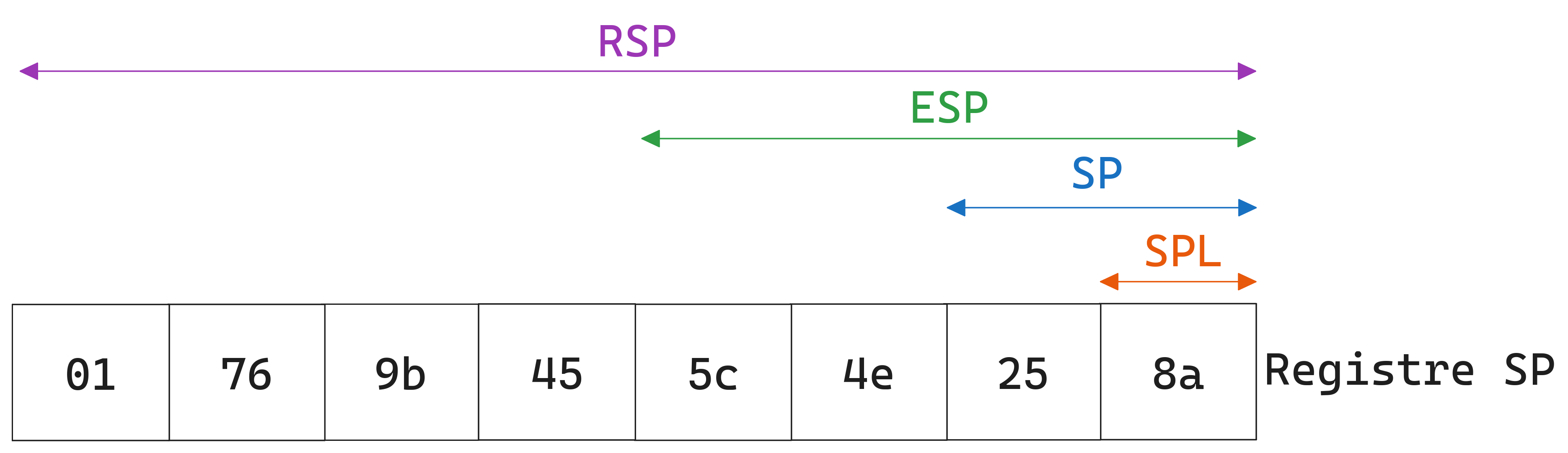
Figure 2 Les différentes manières d’accéder au registre %rsp.#
Pour les nouveaux registres de l’architecture x86_64
[%r8,r15]on utilise plutôt des suffixes pour spécifier la taille à lire ou à écrire.
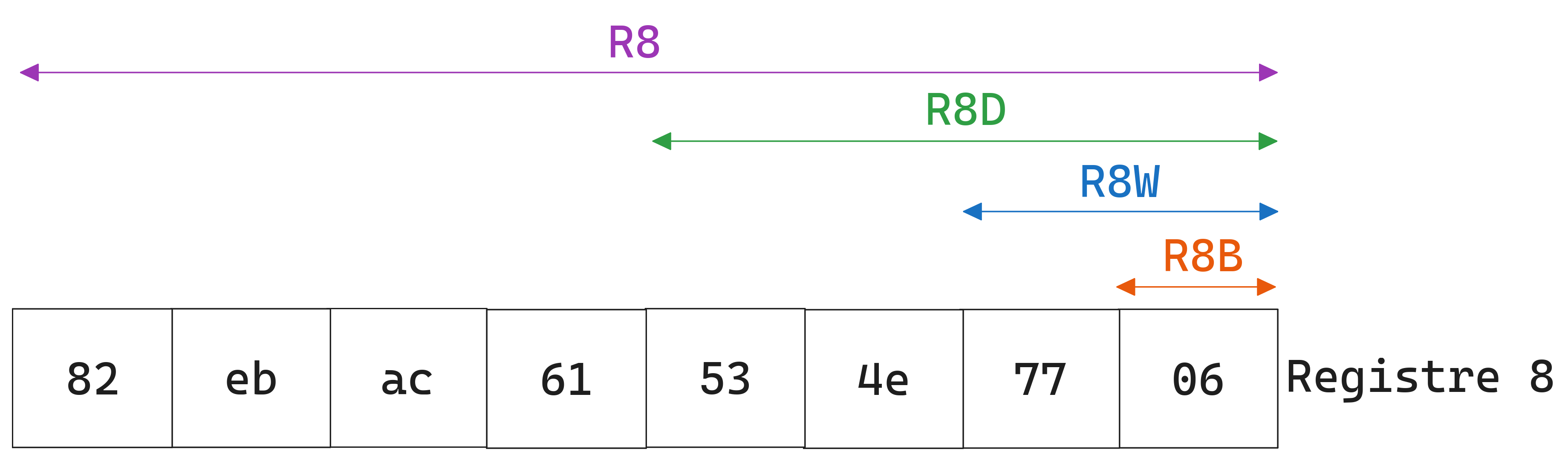
Figure 3 Les différentes manières d’accéder au registre %r8.#
Références:
Le Registre RIP#
Le pointer register
%ripcontient l’adresse mémoire où la prochaine instruction à exécuter est située. Comme vous pouvez le voir dans les captures suivantes, quand le CPU fini d’exécuter l’instructionmovabsqui est à l’adresse0x5129la valeur de%ripest l’adresse de l’instruction suivantemov %eax, %ebxà l’adresse0x5133.

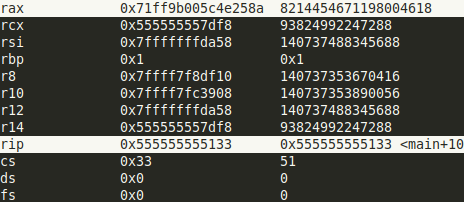
Figure 4 La valeur du %rip est calculée lors de l’exécution d’une instruction.#
Il faut que vous sachiez que les instructions ont des tailles différentes. Elles varient de
1 octetsjusqu’à15 octets. Étant donné qu’en mémoire les données sont stockés par octets. Durant la lecture d’un octet de l’instruction le CPU sait s’il doit interpréter le prochain octet comme faisant partie de cette même instruction grâce aux octets qu’il a déja décodés.Les instructions d’appel et de branchement
jmp,call,ret, … ne font que modifier la valeur de ce fameux registre%rip, en d’autres termes elles changent l’adresse de la prochaine instruction.
Résumé sur les registres#
| 64-bits | 32-bits | 16-bits | 8-bits | Utilisation dans l'ABI Linux AMD64 | Appel de fonction |
|---|---|---|---|---|---|
| rax | eax | ax | ah,al | Valeur de retour | Peut être modifié par la fonction appelée |
| rbx | ebx | bx | bh,bl | Doit être sauvegardé par la fonction appelée | |
| rcx | ecx | cx | ch,cl | 4e argument entier | Peut être modifié par la fonction appelée |
| rdx | edx | dx | dh,dl | 3e argument entier | Peut être modifié par la fonction appelée |
| rsi | esi | si | sil | 2e argument entier | Peut être modifié par la fonction appelée |
| rdi | edi | di | dil | 1erargument entier | Peut être modifié par la fonction appelée |
| rbp | ebp | bp | bpl | Début d'une stack frame | Faire extrêmement attention à son utilisation et à sa sauvegarde |
| rsp | esp | sp | spl | La fin de la pile (top of stack) | Faire extrêmement attention à son utilisation et à sa sauvegarde |
| r8 | r8d | r8w | r8b | 5e argument entier | Peut être modifié par la fonction appelée |
| r9 | r9d | r9w | r9b | 6e argument entier | Peut être modifié par la fonction appelée |
| r10 | r10d | r10w | r10b | Peut être modifié par la fonction appelée | |
| r11 | r11d | r11w | r11b | Peut être modifié par la fonction appelée | |
| r12 | r12d | r12w | r12b | Doit être sauvegardé par la fonction appelée | |
| r13 | r13d | r13w | r13b | Doit être sauvegardé par la fonction appelée | |
| r14 | r14d | r14w | r14b | Doit être sauvegardé par la fonction appelée | |
| r15 | r15d | r15w | r15b | Doit être sauvegardé par la fonction appelée |
Important
Quand vous appelez une fonction il ne faut pas vous attendre à ce que les registres en vert aient gardé leur valeur. Autrement dit, si votre programme assembleur utilise le registre
%rdxil faut qu’il soit sauvegardé (pushq %rdx) avant l’appelcall my_funcet puis restauré après l’appel (popq %rdx).Par contre si une fonction veut utiliser un des registres en rouge, elle doit le sauvegarder avant sa modification et le restaurer avant le retour (
ret).
Le document sur l’ABI AMD64 (section 3.2.3 Parameter Passing) présente dans un tableau plus complet sur l’utilisation de chaque registre. Les sources latex officielles sont sur gitlab, vous trouverez un lien pour télécharger le pdf dans le README.
my_func:
pushq %rbx ; sauvegarde %rbx
pushq %r14 ; sauvegarde %r14
; ...
movq %rdi, %rbx ; modifie %rbx
; ...
movq (%rbx), %r14 ; modifie %r14
; ...
addq %r14, %edx ; modifie %rax
; ...
popq %r14 ; restaure %r14
popq %rbx ; restaure %rbx
ret
main:
; ...
movabs $4523902, %rbx
movl $125, %edx ; utilise %eax
movl $45, %edi
pushl %edx
call my_func
; %edx a été changé par my_func
movl %edx, (%rbx) ; la valeur de %rbx est maintenue par my_func
; maintenant, j'ai besoin de mon %edx
popl %edx
movl %edx, 4(%rbx) ; la valeur initiale de %edx est écrite en adresse mémoire %rbx + 4
; ...
ret
Références:
Les flags et le registre RFLAGS en x86_64#
Lors de l’exécution de certaines instructions, il est intéressant de garder certaines informations sur le résultat de ces dernières, pour rendre certaines instructions inter-dépendantes. Par exemple, si on veut additionner des nombres de taille supérieure à 64-bits, disons 128-bits il est primordial de savoir si l’addition des 64-bits de poids faible a généré une retenue pour le 65ème bit pour avoir un résultat correct (
adc). Il existe plein d’autres cas autre que les jump, où l’on veut avoir des informations sur le résultat de l’instruction précédente.
Le registre RFLAGS : structure et évolution#
En x86_64, on a à notre disposition le registre RFLAGS pour stocker et accéder aux informations décrivant la nature du résultat d’une instruction. En x86(32 bits), le registre se nommait EFLAGS et à l’âge de l’architecture 16-bits FLAGS. Vous pouvez voir comment ce registre fut étendue avec le changements d’architecture dans la figure ci-dessous.
En pratique, le registre RFLAGS décrit aussi des restrictions d’exécution, ainsi une instruction va changer son comportement, voir lever une exception si des restrictions sont actives.
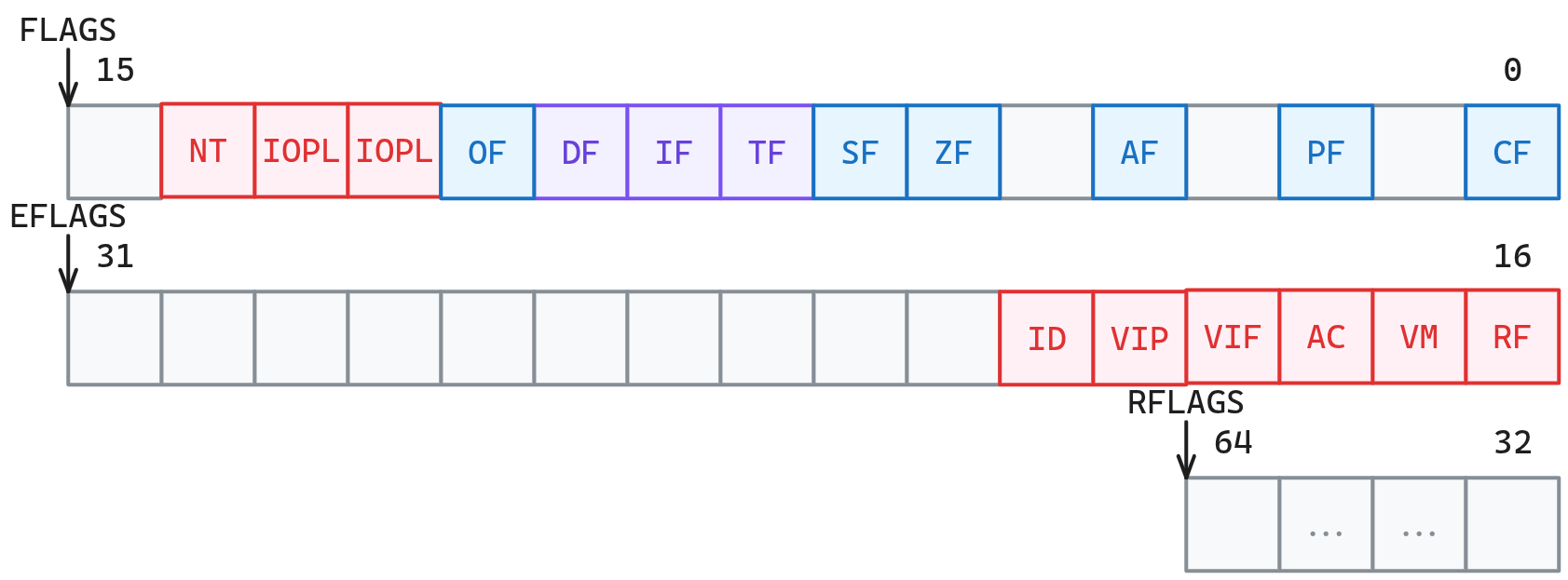
Figure 5 Structure complète du registre RFLAGS.#
Lors du développement de l’architecture, les ingénieurs ont dû choisir quelles informations garder sur le résultat d’une instruction. Pour optimiser un maximum la mémoire, tout en gardant l’utilisation simple, ils se sont limité à un seul registre. Chaque bit du registre indique la présence ou l’absence d’un flag relié à un état. Les bits vides sont réservés, Intel et AMD les utilisent comme ils veulent.
Les différents types de flags#
Les flags sont divisés en 3 groupes:
Status Flags:
CF(Carry Flag): 1 s’il y a eu une retenue au-delà du bit de poids fort du résultat, sinon 0.
PF(Parity Flag): 1 si le nombre de bits à 1 dans les 8-bits de poids faible est pair, 0 si impair.
AF(Auxiliary Carry Flag): 1 s’il y a eu une retenue depuis le bit 3 vers le bit 4, sinon 0.
ZF(Zero Flag): 1 si le résultat est nul, sinon 0.
SF(Sign Flag): 1 si le résultat est négatif, sinon 0.
OF(Overflow Flag): 1 si le résultat d’une opération signée dépasse la capacité du registre (changement de signe inattendu), sinon 0.
Control Flags:
IF(Interrupt Flag): 1 si les interruptions sont actives, 0 si désactivées.
DF(Direction Flag): 1 pour que les adresses soient décrementées lors des instructions iteratives (
rep), 0 pour les incrémenter.TF(Trap Flag): 1 pour appeler une fonction après chaque instruction permettant d’avoir une exécution pas à pas (debug), 0 pour une exécution classique.
System Flags:
IOPL(I/O privilege level).
…
Mécanismes de mise à jour des flags#
La mise à jour des flags nécessite des tests et des écritures, cela prend du temps. Pour ne pas en perdre inutilement, les ingénieurs ont fait en sorte que certaines instructions ne touchent pas aux flags (le
movpar exemple). Et même les instructions mettant à jour les flags, ne touchent pas à tous les flags, seulement ceux nécessaires. Entre autres, l’instructionaddne met à jour que les status flags.En général, on dit que les instructions qui ne font que déplacer des données ne modifient pas les flags. Par contre, celles qui effectuent des calculs mettent à jour les flags nécessaires.
Il existe certaines exceptions d’instructions qui calculent mais ne mettent pas à jour les flags, parmi elles :
notetlea.
Instructions de manipulation des flags#
Il est possible d’accéder au registre RFLAGS via des instructions spéciales :
L’instruction
cmp i1, i2fait une soustractioni2 - i1sans sauvegarder le résultat dans l’opérant destination et met à jour les flags CF, OF, SF, ZF, AF, et PF.L’instruction
test i1, i2fait un bit-wise ANDi2 & i1et met à jour les flags PF, SF, ZF. Entre autres, elle permet de tester si un registre est nultestq %rax, %rax, en étant plus compacte quecmp $0, %rax.Les instructions de la famille
jccvérifient les flags pour charger l’adresse spécifiée dans le registre rip ou pas (rip pointe vers l’instruction suivante).
pushf et popf
pushf/popf empile/dépile le registre RFLAGS sur/depuis la pile d’une certaine manière. Les descriptions de pushf et popf expliquent plus en détails les restrictions de ces instructions. En se limitant à l’architecture 64-bits, on a:
Les flags
VMetRFne sont jamais push, ils sont toujours forcés à zéro.Par défaut, l’instruction (mnemonic)
pushfqempile les 8 octets de RFLAGS. Et on écritpushfpour empiler que les 2 octets FLAGS. Il est impossible d’empiler que les 4 octets EFLAGS. Même si les instructions ont le même opcode0x9C, le préfixe0x66permet de passer en mode 16-bits.Malheureusement, un différent assembleur peut ne pas séparer les deux mnemonics
pushfetpushfq.
Pour ce qui est de
popf, le cpu va mettre à jour RFLAGS en rapport à son mode actuel Table 4-16.
Références:
Les modes d’adressage#
Commençons par le commencement : l’adressage, c’est tout simplement la façon dont on dit au processeur “hé, va chercher/mettre cette donnée à tel endroit !”.
Modes Directs#
1. Mode d’adressage immédiat#
Le mode le plus simple, c’est l’adressage immédiat. Imaginez que vous dites directement “le nombre c’est 42”. Pas besoin de chercher ailleurs, la valeur est directement dans l’instruction. C’est comme écrire une constante dans du code C ou autre.
; AT&T
movq $42, %rax ; Charge la valeur 42 dans rax
addq $10, %rbx ; Ajoute 10 à rbx
2. Mode d’adressage par registre#
L’adressage par registre utilise directement les registres du processeur pour stocker et manipuler les données. C’est le mode d’accès le plus rapide, car les registres sont intégrés au cœur du CPU. Ils constituent un espace de stockage limité mais immédiatement accessible, similaire à des variables globales en C, mais en nombre fixe et restreint.
; AT&T
movq %rbx, %rax ; Copie rbx dans rax
xorq %rax, %rax ; Mise à zéro rapide de rax
3. Mode d’adressage mémoire direct#
Maintenant, parlons de l’adressage mémoire direct, ce mode utilise une adresse mémoire fixe. Vous dites au processeur “va chercher ce qu’il y a à l’adresse 0x1234”. C’est utile pour accéder à des variables globales ou des constantes dont on connait l’adresse à la compilation (pas de malloc).
; AT&T
movq value, %rax ; Charge depuis l'adresse 'value'
movq %rbx, target ; Stocke dans l'adresse 'target'
4. Modes Indirects#
Les choses deviennent plus intéressantes avec l’adressage indirect. Ici l’adresse qu’on cherche à accéder n’est pas directement accessible, soit une lecteur ou un calcul sont nécessaires.
1. Mode d’adressage indirect par registre#
L’adressage indirect peut utiliser un registre comme pointeur vers la mémoire. Au lieu de dire “va à telle adresse”, on dit “va à l’adresse qui est stockée dans ce registre”. C’est la base de la manipulation des pointeurs.
; AT&T
movq (%rbx), %rax ; Charge depuis l'adresse contenue dans rbx
movq %rax, (%rcx) ; Stocke à l'adresse contenue dans rcx
2. Mode d’adressage avec déplacement#
Ce mode combine un registre et un déplacement pour calculer l’adresse finale. Parfait pour les tableaux et structures.
; AT&T
movq 10(%rbx), %rax ; Adresse = rbx + 10
movq %rax, 18(%rbx) ; Stocke à rbx + 18
3. Mode d’adressage RIP-relative#
Le mode d’adressage RIP-relative est spécifique à l’architecture x86-64. Ce mode est fondamental pour le Position Independent Code (PIC). Les adresses sont calculées relativement à la position courante du pointeur d’instruction (rip), permettant au code d’être chargé à n’importe quelle adresse en mémoire virtuelle sans nécessiter de relocation. C’est une technique fondamentale pour les bibliothèques partagées. L’assembler (ex:gnu as ou nasm) et le linker se charge de calculer le deplacement et le mettre dans le code machine finale.
; 1. Déplacement constant :
; AT&T
movq 1234(%rip), %rax ; Accède à l'adresse rip+1234
; (1234 octets après la fin de l'instruction courante, i.e le début de l'instruction suivante)
; 2. Symboles :
; AT&T
movq symbol(%rip), %rax ; Accède au symbole de manière relative
; Plus efficace et plus compact que l'adressage absolu
Important
En syntaxe AT&T, pour les instructions de contrôle de flux (jmp, call), le préfixe * distingue l’adressage absolu de l’adressage relatif :
; AT&T
jmp label ; Adressage relatif à rip
jmp *label ; Adressage absolu : utilise l'adresse fixe de 'label'
call *%rax ; Appel indirect : utilise l'adresse contenue dans rax
Sans *, le code machine encode un déplacement relatif depuis rip (plus compact, position-independent). Avec *, il encode une adresse absolue (nécessaire pour les sauts indirects).
4. Mode d’adressage base + index + échelle + déplacement#
Le mode le plus complet, permettant des calculs d’adresse complexes.
; AT&T
; Format général : déplacement(base,index,échelle)
movq 8(%rbx,%rcx,4), %rax ; déplacement=8, base=rbx, index=rcx, échelle=4
; Adresse = rbx + (rcx*4) + 8
movq 8(%rbx,%rcx), %rax ; déplacement=8, base=rbx, index=rcx, échelle=1 (implicite)
; Adresse = rbx + (rcx*1) + 8
movq (%rbx,%rcx), %rax ; déplacement=0 (omis), base=rbx, index=rcx, échelle=1 (implicite)
; Adresse = rbx + (rcx*1)
Notes sur la performance
Les modes impliquant des accès mémoire sont généralement plus lents
L’utilisation de l’échelle peut ajouter des cycles supplémentaires
Les registres sont toujours les mémoires les plus rapides à lire et à écrire.
Références: